
kuromojiで記号を捨てないようにする
Aapache Solrを使って何かをするシリーズその2です
その1はこちら
kuromoji
Solrにビルドインされている日本語の形態素解析です。 検索サービスを運用しているときに、よく検索にヒットしないケースに当たるんだけど、 形態素解析の文字の切れ方が要因でうまくヒットできてないとかが結構ありがちなので、 それの確認方法を試します。
analysis
Solrにはインデックス時に文字列がどう扱われるか?を見ることのできます。 前回作成したDashboardのcovidコアを開いて、analysisのリンクを開きます。
適当な文字列を入れて、形態素解析結果が取得できればOKです。クエリ方のテキストエリアに入れると、クエリも分解されて、マッチされた部分の色が変わります。
kuromojiの設定を変更して、記号を捨てないようにする
例えば、
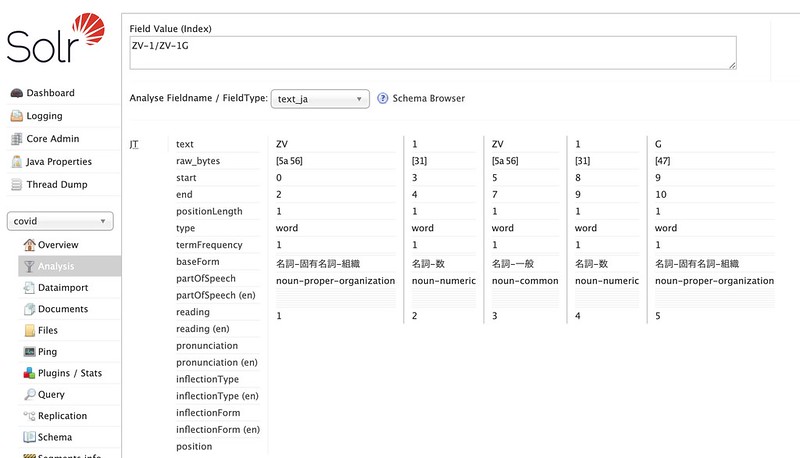
ZV-1/ZV-1G
をインデクスすると、自動でハイフンとスラッシュはなくなります。 これはこれでいいですが、特に型番のとかの際に不都合が出たり、そもそもハイフン検索できないの?みたいなこともあります。
fieldtypeの追加
設定変更をするためにfieldtypeを追加します。これもマネージドスキーマを使います。 具体的には、DiscardPunctuationをfalseに設定したfieldtypeを作成します。 前回作成したコアを流用します。
/*addfieldtype.json*/
{
"add-field-type" : {
"name":"text_ja_discardpuncruation",
"class":"solr.TextField",
"autoGeneratePhraseQueries":"false",
"positionIncrementGap":"100",
"analyzer" : {
"tokenizer":{
"class":"solr.JapaneseTokenizerFactory",
"mode": "search",
"discardPunctuation": "false",
"userDictionary": "User.txt"
},
"filters":[
{ "class":"solr.CJKWidthFilterFactory" },
{ "class":"solr.JapaneseKatakanaStemFilterFactory","minimumLength":"4" },
{ "class":"solr.LowerCaseFilterFactory" }
] }}
}
##schemaAPIにcurlでjsonを投げる
#!/bin/sh
curl -X POST -d @addfieldtype.json -H 'Content-type:application/json' http://localhost:8983/solr/covid/schema
追加したfieldtypeの確認
analisysページを開き直して、Fieldtypeから、text_ja_discardpuncruationを選択して、文字列を入力します。
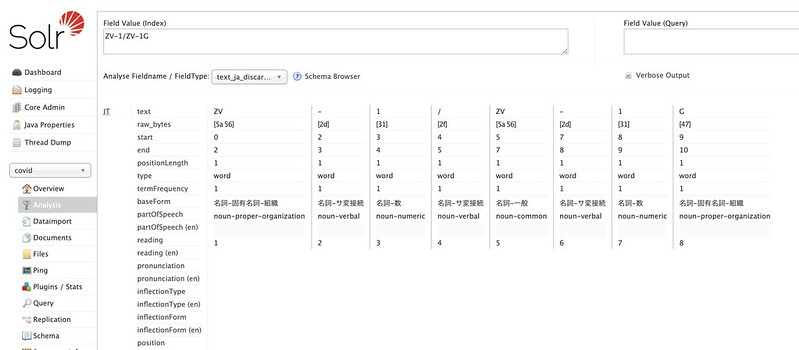
形態素解析で記号が捨てられないように設定できました。
github
今回のgithubです。前回のものを流用したのでshellスクリプトだけ追加しました。